CSV 파일
CSVcomma-separated values (쉼표로 값이 구분된 텍스트) 파일 포맷은 데이터를 저장하고 공유하는 매우 간편한 포맷이다. CSV 파일은 숫자나 문자열로 구성되어 있는 표(혹은 스프레드시트) 형태의 데이터가 일반 텍스트plain-text로 저장된다. 일반 텍스트로 저장되므로 이를 저장하거나 전송하고 처리할 수 있는 프로그램이 다양하다. 이 점이 엑셀 파일과 비교했을 때 CSV 파일의 가장 큰 장점이다. 엑셀과 같은 스프레드시트 프로그램뿐만 아니라 워드프로세서 또는 간단한 텍스트 편집기로도 CSV 파일을 처리할 수 있다. 반면에 엑셀 파일은 그것을 처리할 수 있는 프로그램이 매우 제한적이다. 엑셀은 그 자체로 강력한 도구지만, 엑셀 파일은 엑셀에서 수행할 수 있는 작업만이 가능하다면, CSV 파일은 자신이 원하는 작업에 적합한 툴로 데이터를 전송하거나 파이썬을 사용하여 직접 만든 툴에서도 사용 가능하다.
물론 CSV 파일로 작업할 때에는 엑셀 파일만의 편리함은 사라진다. 예를 들어 엑셀의 모든 셀은 각각 정의된 자료형(숫자, 텍스트, 통화, 날짜 등)을 갖지만 CSV 파일의 각 셀은 자료형이 없는 원시 데이터raw data이다. 1장에서 살펴본 것처럼 파이썬은 다른 자료형을 인식하고 정의하는 데 뛰어나므로 그것이 큰 문제가 되진 않는다. 또 다른 불편한 점은 CSV 파일은 수식 없이 오로지 데이터만 저장된다는 점이다. 하지만 데이터 저장소(CSV 파일)와 데이터 처리(파이썬 스크립트)가 분리됨으로써 다른 데이터셋에 똑같은 처리 과정을 보다 쉽게 적용할 수 있게 된다. 뿐만 아니라 이러한 분리를 통해 데이터 자체와 데이터 처리 과정 모두에서 오류를 찾아내기가 더욱 쉬워지고, 오류가 전파되는 것은 더욱 어려워진다.
이제 본격적인 작업을 위해서 CSV 파일을 하나 만들어보자. 다음 그림과 같이 직접 입력하거나 혹은 깃허브 저장소에서 파일을 다운로드해도 된다.(역주_ 깃허브는 CSV 파일을 표 형태로 렌더링해서 출력한다. 이 파일을 다운로드하려면 [Raw] 버튼을 누르고 브라우저의 ‘파일 > 다른이름으로 저장’ 등의 메뉴를 이용하면 된다. 이하 책의 예제 코드, 입력 파일, 출력 파일 모두 원서 깃허브 저장소의 각 장에 해당하는 폴더에 책과 같은 파일명으로 들어 있으므로 이를 다운로드해서 실습에 사용하면 편리하다.)
1. [그림 2-1]과 같이 새로운 스프레드시트를 열고 데이터를 입력한다.
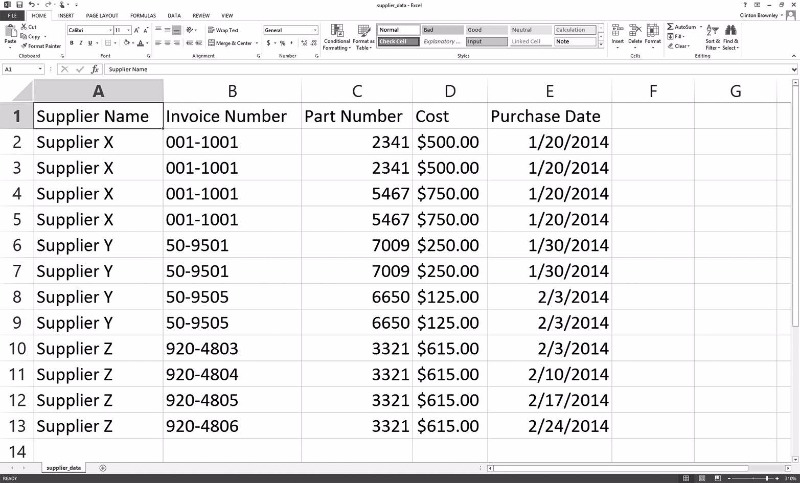
[supplier_data.csv file 파일에 데이터 입력]
2. 이 파일을 supplier_data.csv라는 이름으로 바탕화면에 저장한다.
supplier_data.csv 파일이 실제로 일반 텍스트 파일인지는 다음과 같이 확인할 수 있다.
1 바탕화면에서 supplier_data.csv 파일을 찾는다.
2 파일을 선택하고 마우스 오른쪽 버튼을 클릭한다.
3 ‘연결 프로그램’을 선택한 다음 메모장, 노트패드++, 서브라임텍스트 등의 텍스트 편집기를 선택한다.
텍스트 편집기에서 파일을 열면 [그림 2-2]와 같이 나올 것이다.
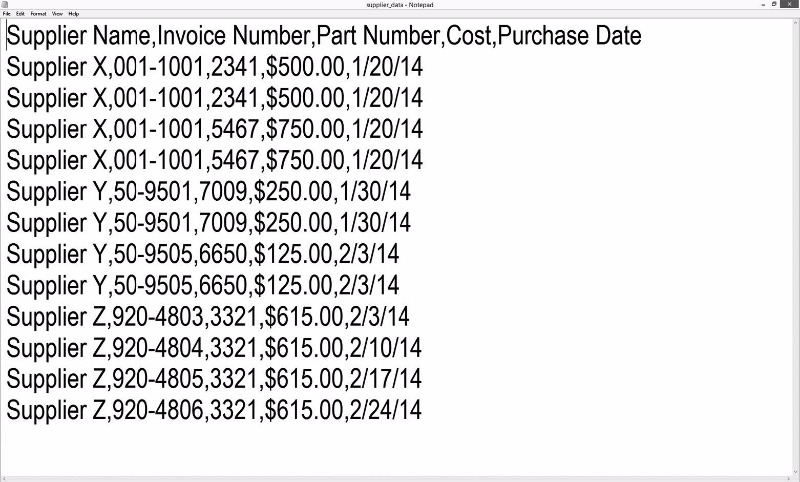
그림 2-2 메모장으로 열어본 supplier_data.csv 파일
보다시피 이 파일은 단순한 텍스트 파일이고 각 행마다 다섯 개의 값이 쉼표로 구분되어 저장되어 있다. CSV 파일에서 구분자로 사용된 쉼표는 엑셀 파일의 열에 해당한다고 볼 수 있다.
CSV 파일 읽고 쓰기
[1] csv 모듈을 사용하지 않는 기본 파이썬 코드
이제 기본 파이썬으로 CSV 파일을 읽고 처리하고 작성하는 방법에 대해 알아보자(내장된 csv모듈 역시 사용하지 않을 것이다). 이 예제를 통해서 csv 모듈의 작동 원리에 대해서도 알 수 있다. CSV 파일 작업을 위해 새로운 파이썬 스크립트 1csv_read_with_simple _parsing_and_write.py를 작성한다. 스파이더 또는 텍스트 편집기에 아래와 같이 코드를 입력한 뒤에 바탕화면에 1csv_read_with_simple_parsing_and_write.py라는 이름으로 스크립트를 저장한다.
1 #!/usr/bin/env python3
2 import sys
3 input_file = sys.argv[1]
4 output_file = sys.argv[2]
5 with open(input_file, 'r', newline='') as filereader :
6 with open(output_file, 'w', newline='') as filewriter :
7 header = filereader.readline()
8 header = header.strip()
9 header_list = header.split(',')
10 print(header_list)
11 filewriter.write(','.join(map(str,header_list))+'')
12 for row in filereader:
13 row = row.strip()
14 row_list = row.split(',')
15 print(row_list)
16 filewriter.write(','.join(map(str,row_list))+''
스크립트를 실행하고 출력되는 결과를 확인하기 전에 먼저 각 코드가 어떤 일을 하는지 살펴보자. 코드의 라인 번호를 토대로 각 코드 블록에 대해 차례대로 설명하겠다.
#!/usr/bin/env python3
import sys
1행은 1장에서 살펴본 것처럼 다른 운영체제 간에 통용될 수 있는 스크립트를 만들게 해주는 셔뱅이다. 2행에서는 sys 모듈을 임포트한다. 파이썬에 기본으로 내장되어 있는 sys 모듈은 명령 줄에서 추가적으로 입력된 인수를 스크립트로 넘겨준다.
input_file = sys.argv[1]
output_file = sys.argv[2]
4행과 5행에서는 sys 모듈의 argv라는 인수를 사용한다. 이 인수는 명령 줄 실행 시에 추가적으로 입력되는 인수를 리스트 자료형으로 받는다. 다음은 윈도우 환경에서 입력되는 CSV 파일을 읽고, 출력 CSV 파일을 쓰는 데 사용되는 일반적인 형태의 명령 줄 인수이다.
python script_name.py "C:pathoinput_file.csv" "C:pathooutput_file.csv"
첫 번째 단어인 python은 파이썬을 사용하여 나머지 명령 줄 인수를 처리하도록 명령한다. 파이썬은 나머지 인수를 argv라는 특별한 리스트에 할당한다. 리스트의 첫 번째 위치인 argv[0]는 script_name.py 파일을 가리킨다. 그다음 명령 줄 인수는 입력 CSV 파일의 경로와 파일명인 "C:pathoinput_file.csv"이다. 파이썬은 이 값을 argv[1]에 할당하므로 위에서 본 파이썬 스크립트의 4행에서 이 값을 input_file 변수에 할당한다. 마지막 명령 줄 인수인 "C:pathooutput_file.csv"는 출력 CSV 파일의 경로와 파일명이다. 파이썬은 이 값 역시 argv[2]에 할당하고 5행에서 이 값을 output_file 변수에 할당한다.
with open(input_file, 'r', newline=' ') as filereader :
with open(output_file, 'w', newline=' ') as filewriter :
7행은 input_file을 filereader라는 파일 객체로 열어주는 with 문이다. open() 함수에서 'r'은 읽기 모드를 할당한다. 이는 input_file이 읽기 위해 열렸음을 의미한다. 8행은 output_file을 파일 객체인 filewriter로 여는 명령문이다. 'w'는 쓰기 모드를 할당한다. 즉 output_file은 쓰기 위해 열렸음을 의미한다. 1.5.3절에서 보았듯이 with 문은 with 문이 종료될 때 자동으로 파일 객체를 닫으므로 편리하다.
header = filereader.readline()
header = header.strip()
header_list = header.split(',')
9행에서는 filereader 객체의 readline() 함수를 사용하여 입력 파일의 첫 번째 행(헤더행)을 문자열로 읽고 이를 header라는 변수에 할당한다. 10행에서는 strip() 함수를 사용하여 header에 있는 문자열의 양끝에서 공백, 탭 및 개행문자() 등을 제거한 뒤, header에 다시 할당한다. 11행에서는 split() 함수를 사용하여 문자열을 쉼표 기준으로 구분하여 리스트에 할당한다. 리스트의 각 원소는 입력 파일의 각 열의 헤더이며 header_list라는 변수로 할당된다.
print(header_list)
filewriter.write(','.join(map(str,header_list))+'')
12행은 header_list의 값(즉 헤더 행)을 화면에 출력하는 print() 문이다. 13행에서는 filewriter 객체의 write() 함수를 사용하여 header_list의 각 값을 출력 파일에 쓴다. 이 한 줄에는 많은 작업이 들어 있으므로 괄호 안쪽에서부터 살펴보겠다. map() 함수는 header_list의 각 원소에 str() 함수를 적용하여 각 원소를 문자열로 만든다. 그다음 join() 함수는 header_list의 각 값 사이에 쉼표를 삽입하고 리스트를 문자열로 변환한다. 그다음 개행문자를 문자열 끝에 추가한다. 끝으로 filewriter 객체는 그 문자열을 출력 파일의 첫 번째 행에기록한다.
for row in filereader:
row = row.strip()
row_list = row.split(',')
print(row_list)
filewriter.write(','.join(map(str,row_list))+'')
14행에서는 for 반복문을 작성하여 입력 파일의 나머지 행을 반복한다. 15행은 strip() 함수를 사용하여 row라는 변수의 문자열 양끝에서 공백, 탭 및 개행문자를 제거한 뒤r ow에 다시 할당한다. 16행에서는 split() 함수를 사용하여 문자열을 쉼표 기준으로 분리하여 리스트에 할당한다. 리스트의 값은 각 행의 열 값이고, row_list라는 변수에 리스트가 할당된다. 17행에서는 row_list의 값을 화면에 출력하고 18행은 값을 출력 파일에 기록한다. 이 스크립트는 입력 파일의 모든 행에 대해서 15행에서 18행까지를 실행한다. 이 네 줄은 14행의 for 반복문 아래에 들여쓰기가 적용되어 있기 때문이다.
명령 프롬프트 창을 열고 바탕화면 혹은 파이썬 스크립트를 저장한 곳으로 이동하고 다음 한 줄을 입력한 다음 엔터 키를 누른다.
python 1csv_simple_parsing_and_write.py supplier_data.csv 1output.csv
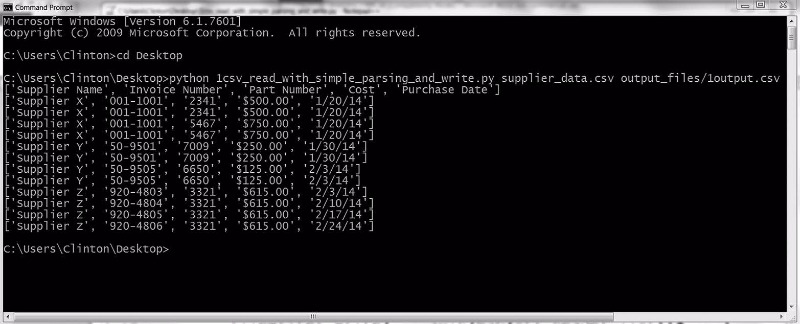
그림 2-6 파이썬 스크립트 실행 결과
입력 파일의 모든 행이 화면에 출력되고 출력 파일에 기록된다. 대부분의 경우 입력 파일에 모든 데이터가 이미 존재하므로 입력 파일에서 출력 파일로 모든 데이터를 똑같이 다시 쓰는 경우는 거의 없을 것이다. 다만 이 예제에서 filewriter.write()문을 포함해 출력 파일에 특정 행을 쓰는 방법을 살펴봤으므로, 이를 다양한 비즈니스 분석 상황에서 유용하게 응용할 수 있을 것이다.
이전 글 : IT 트렌드 스페셜 리포트 2018

최신 콘텐츠
