들어가며…
안녕하세요? 정리하는 개발자 워니즈입니다. 이번시간에는 쓸모 있는 AI 서비스 만들기라는 책에 대해서 서평을 해보려고합니다. 최근 ChatGPT와 관련하여 AI관련 내용이 굉장히 화두가 되고 있는데요. 필자도 이러한 AI에 대해 관심이 가기 시작했습니다. 대체 어떻게 학습을 하고 판단을 내리고 결과를 실행하는 것일지 너무 궁금해졌습니다. 이번 책을 통해서 그 내용에 대해서 간단히라도 도움을 받을 수 있을 것이라 생각하게 됐습니다. 그럼 각 장 별로 어떤 내용이 있는지 정리해보겠습니다.
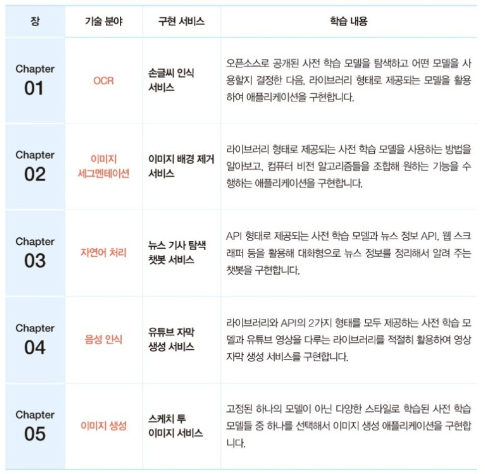
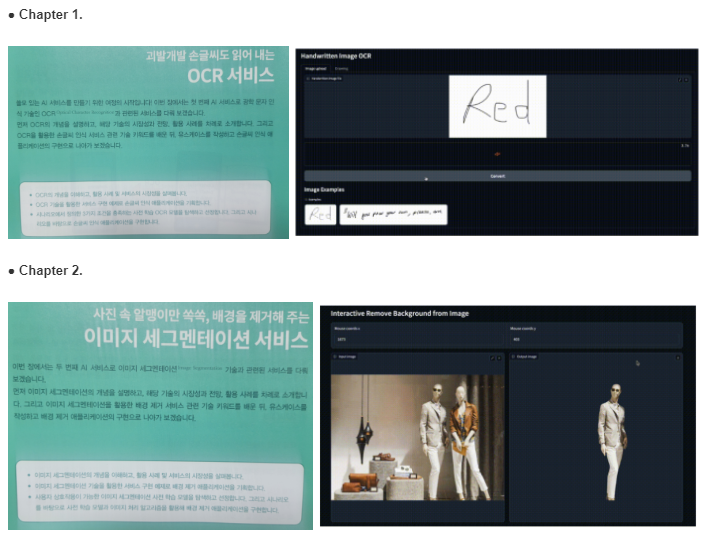
1장 괴발 개발 손글씨도 읽어 내는 OCR 서비스
OCR(Optical Character Recognition) 기술은 이미지 속에 들어 있는 문자를 컴퓨터가 인식할 수 있는 디지털 문자로 변환해주는 기술입니다. 이를 통해서 다양한 종류의 문서 및 이미지에 포함된 텍스트를 디지털 데이터로 변환할 수 있는 OCR 기술을 채택하는 기업이 나날이 늘어나고 있습니다.
그러고보니 며칠전 필자가 코인 관련 월렛을 생성하면서 주민등록증을 사진으로 찍었는데 모든 글자들이 텍스트 형태로 자동 변환되는것을 경험했습니다. 이미 오래전부터 사용된 기술이긴했지만 그 이면에는 OCR이라는 AI 기술이 적용된 것이라는것을 책을 통해서 알게 됐습니다.
기본적으로 각 챕터의 구성은 기술 키워드를 알 수 있도록 설명하고 있습니다. OCR과 관련한 내용으로는 다음과 같은 개념들이 있습니다.
인코더-디코더
인코더-디코더구조는 복잡한 입력 데이터를 압축하고 재구성하는 딥러닝 모델의 일반적인 구조를 의미합니다.
토크나이저
토크나이저는 우리가 사용하는 언어를 컴퓨터가 이해하고 처리할 수 있는 형태로 바꿔주는 중요한 도구입니다.
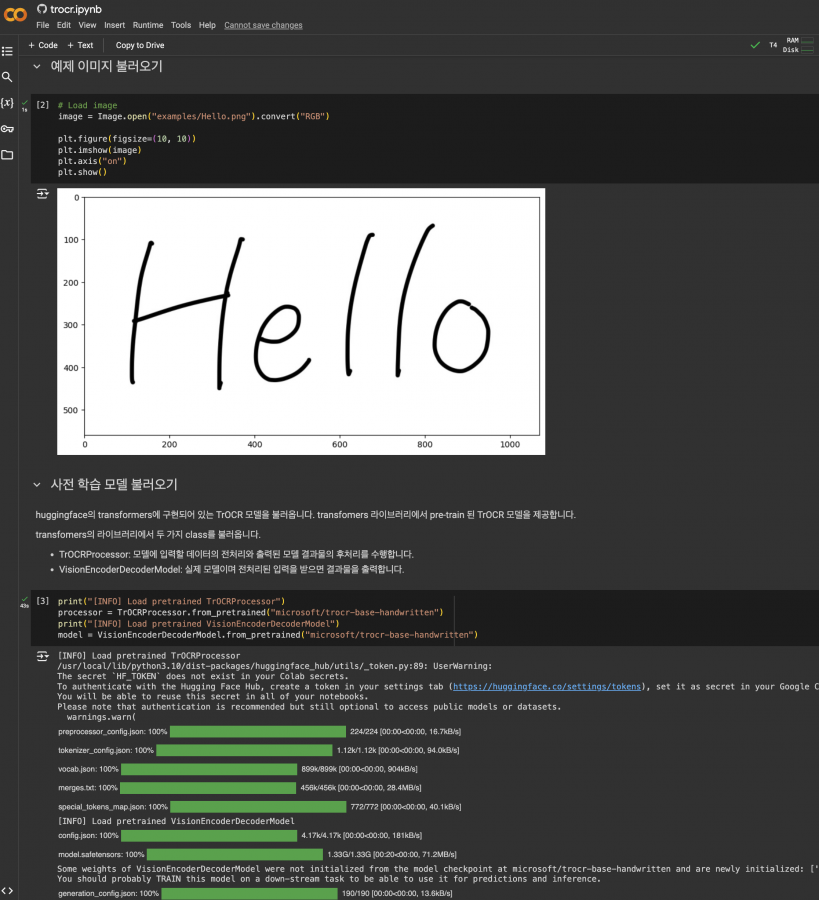
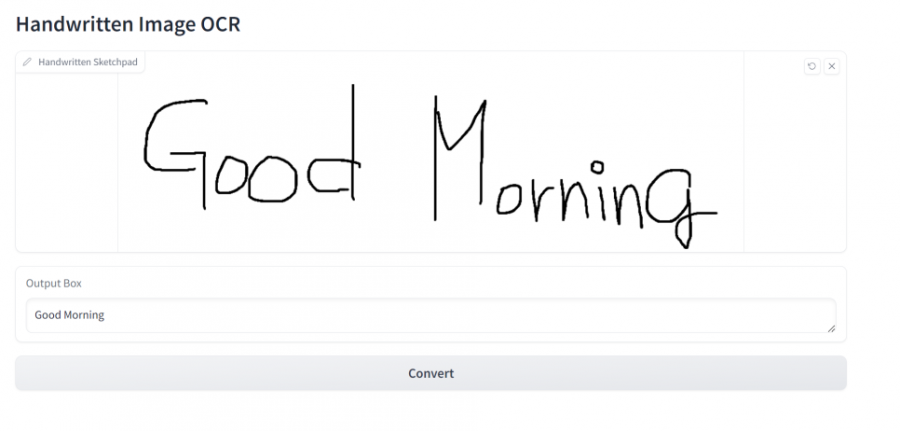
상위 2가지 개념을 통해서 서비스를 구현하는 내용으로 이어집니다. 직접 손글씨로 작성한 내용을 OCR을 통해서 텍스트로 변환하는 어플리케이션입니다. 별도로 AI를 직접 구현하는 것이 아니라 이미 오픈소스로 알려진 라이브러리를 이용하는 부분에 대해서 소개를 하고 있습니다.
최근 AI 분야의 논문들은 모델을 구현한 코드 및 사전 학습 모델과 학습에 사용한 데이터셋까지도 함께 배포하는 경우가 많이 있다고 합니다. 책에서는 TrOCR이라는 모델에 대해서 설정하고 테스트하는 부분에 대해서 소개하고있습니다. 소스코드도 간단하게 소개를 하고 있어서 책을 읽으면서 직접 실습도 해볼수 있도록 구성한 내용이 유익했습니다.
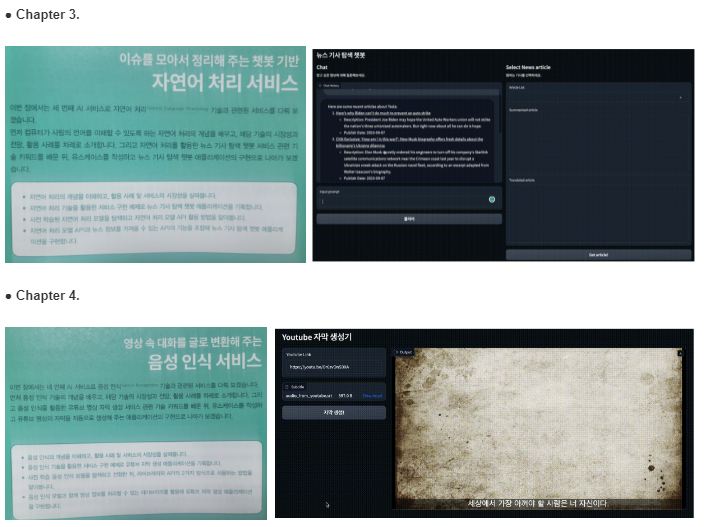
2장 이미지 세그멘테이션 서비스
이미지 세그멘테이션(Image Segmentation) 기술은 컴퓨터가 디지털 이미지나 영상에서 데이터를 추출하고 해석할 수 있도록 하는 컴퓨터 비전 기술 중의 하나로, 이미지 내의 특정 객체를 픽셀 단위로 분리하는 기술입니다.
이미지 세크멘테이션은 객체의 정확한 형태까지 인식하는 기술로 객체 인식 기술(Object Detection)과는 다소 상이한 부분에 대해서 설명하고 있습니다. 객체 인식 기술은 해당 객체의 크기 및 위치만 인식합니다. 전쟁 영화 같은 부분에서 전투 비행기를 타고 가면서 적을 타겟팅하는것이 객체 인식 기술이 사용된것이 아닌가 생각하게 됐습니다.
이미지 세그멘테이션의 활용 사례는 의료 이미지 분석 서비스, 자율주행 서비스, 영상 분석 서비스에서 활용 되고 있습니다.
이미지 세그멘테이션 서비스와 관련한 기술에는 다음과 같은 것이 있습니다.
클래스
클래스는 분류 문제에서 대상이 될 수 있는 여러 카테고리 중 하나를 의미합니다.
세그멘테이션 마스크
이미지 세크멘테이션의 목적이 사람과 배경을 구분하는 것이라면 세그멘테이션 마스크에서 사람에 해당하면 1, 배경이면 0으로 표현할 수 있습니다.
바운딩 박스
이미지 내의 관심 객체 주위를 사각형으로 둘러싸는 것을 의미합니다.
책에서 소개하는 모델은 Segment Anything Model(SAM)이 있습니다. 메타에서 2023년 4월에 공개한 파운데이션 모델로, 이미지 세그멘테이션에 특화된 파운데이션 모델이라고 설명하고 있습니다. 사용자의 클릭을 점 좌표로 변경해서 SAM의 세그멘테이션 프롬프트로 입력하면, 사용자가 클릭한 위치의 객체를 세그멘테이션 할 수 있습니다.
예제 어플리케이션으로는 이미지를 업로드하고 마우스로 클릭하면 SAM을 통해서 이미지 점 좌표로 변경후 SAM에 의해서 특정 영역이 출력(배경이 제거되는)되는 어플리케이션입니다.
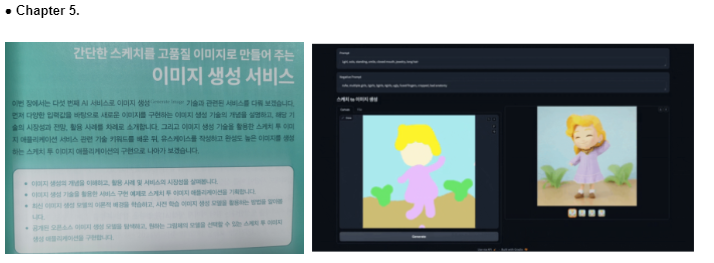
3장 자연어 처리 서비스
필자는 해당 챕터가 가장 관심이 많이 갔습니다. 최근에 챗봇을 개발하고 있는데요. 자연어 처리를 통해서 좀 더 사람과 대화하듯이 만들고 싶었습니다. 그래서 자연어 처리를 어떻게 접목 시킬지를 고민하고 있었는데 해당 챕터를 읽으면서 많은 부분 배우게 된것 같습니다.
사람이 일상적으로 사용하는 언어를 자연어(Natural language)라고 합니다. 자연어 처리 기술은 컴튜터가 이러한 자연어를 이해하고 사용할 수 있도록 도와주는 기술입니다. 보통의 활용 사례는 추로 챗봇 혹은 채팅 서비스에 많이 적용되는 것 같습니다. 감정 분석 서비스, 번역 서비스 등에서 활용 되고 있다고 설명하고 있습니다.
자연어 처리와 관련한 기술 키워드에 대해서 소개하고 있습니다.
자연어
언어 모델
단어나 문장, 문단 단위로 자연어 데이터를 입력받은 후, 다음에 올 단어나 문자열을 예측하는 모델입니다. 문장 생성, 기계 번역, 음성 인식 등 여러 응용 분야에서 사용되고 있습니다.
초거대 언어 모델
LLM은 일반적인 언어 모델보다 훨씬 큰 규모의 언어 모델입니다. 파라미터와 방대한 데이터를 학습한 모델로 일반화 성능이 뛰어납니다.
책에서 소개하는 LLM의 대표적인 모델로는 GPT를 소개하고있씁니다. GPT는 OpenAI에서 개발한 자연어 생성 모델입니다. GPT는 세가지 약자로 다음을 함축하고 있습니다.
Generative – 무언가를 생성하거나 만들어 내는 능력
Pre-Trained – 대량의 데이터셋으로 미리 학습
Transformer – 핵심 아키텍처가 트랜스포머로 구성
관련한 실습 어플리케이션은 프롬프트 창을 통해서 챗봇에 입력합니다. 질문에 해당하는 여러 기사를 정리해서 제공하고, 사용자가 선택하게 되면 스크래핑을 통해서 요약 및 번역을 제공하는 서비스 입니다. 위의 GPT 모델을 이용해서 손쉽게 구현하는 부분에 대해서 소개하고 있습니다.
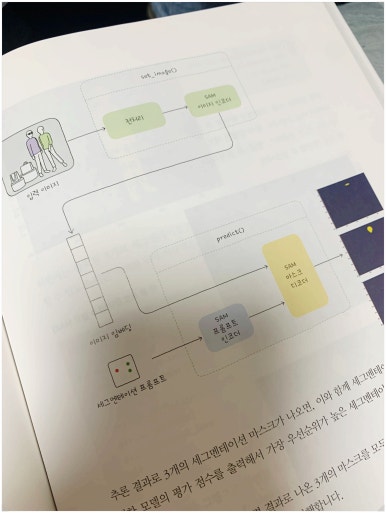
4장 음성 인식 서비스
음성 인식은 우리 주변에서 너무나도 많이 사용하고 있습니다. 필자는 네비게이션에서 주로 많이 활용하는데요. 목적지를 음성으로 입력하면 텍스트로 변환후 목적지를 선택할 수 있게 제공하고 있습니다. 이렇게 음성을 인식하고 텍스트로 변환해주는 서비스에 대해서 소개를 하고 있습니다.
활용 사례는 위에 이야기한대로 우리 주변에서 많이 사용되고 있습니다. 스마트폰 가상 비서 서비스, 자동차 내비게이션 서비스, 음성 메모 서비스에 대해서 소개하고 있습니다.
음성 인식 기술에서 알아야 할 키워드는 다음과 같습니다.
자동 음성 인식
스펙트로그램
시간에 따른 소리 주파수의 변화를 2차원 이미지로 표현한 그래프입니다. 음성 인식 기술에서 스펙토그램은 음성 신호를 분석하고 처리하는데 중요한 역할을 합니다.
해당 챕터에서 예제로 만드는 어플리케이션은 유튜브 영상의 URL을 입력하면 자동으로 번역 스크립트를 작성해주고 영상을 다시 제작해주는 어플리케이션을 만드는것에 대해서 소개하고 있습니다.
모델은 위스퍼라는 것을 선정하고 있습니다. 위스퍼는 2022년 9월에 OpenAI에서 공개한 자동 음성 인식 모델입니다. 이 모델은 음성 인식 작업 및 텍스트 변환 작업을 학습하기 위해 웹에서 수집한 약 680,000시간 분량의 다국어 음성 데이터를 학습했다고 소개하고 있습니다.
5장 이미지 생성 서비스
필자는 해당 챕터에 대해서도 관심이 많은데요. 스크립트를 입력하면 지금까지 없던 새로운 이미지를 생성해주는 것이 너무나 신기했습니다. 화가라는 직업이 무색해질 정도로 정말 창의적이고 새로운 그림 혹은 이미지들을 많이 생성하는 것 같습니다.
이미지 생성 서비스, 기존 이미지 기반 새 이미지 생성 서비스, 예술 작품 생성 서비스 등 다양한 예술 분야에서 활용 되고 있습니다.
이미지 생성 서비스 관련하여 알아야할 키워드는 다음과 같습니다.
오토인코더
입력 데이터를 저차원 표현으로 인코딩한 후, 이를 다시 원래의 고차원 데이터로 복원하는 과정을 학습하는 비지도 학습 모델
잠재 공간
원본 데이터의 복잡한 특성을 보다 간결하고 관리하기 쉬운 형태로 변환한 공간을 의미
해당 챕터에서 소개하고 있는 모델에 앞서 디퓨전 개념에 대해서 설명하고 있습니다. 디퓨전은 물리학의 확산개념에서 영감을 받은 모델입니다. 이미지에 잡음(Noise)이 확산되는 것으로 소개를 하고 있습니다. 이러한 잡음의 정도를 어느정도 제거해야되는지를 예측하는것이 잡음 예측기라고 합니다. 이러한 잡음을 제거하면서 점차 선명한 특정 이미지를 생성할 수 있다고 소개하고 있습니다.
이러한 디퓨전의 개념은 초창기에 잡음을 계산하고 예측하는데 컴퓨팅 자원이 많이 소모되어 점차 발전하게 됐습니다. 그러면서 등장한것이 앞서 소개한 잠재 공간 활용 입니다. 복잡한 데이터를 간결하고 관리하기 쉬운 형태로 변환한 공간을 의미합니다. 이러한 발전을 통해서 현재는 좀더 빠르게 처리할 수 있도록 되었다고 소개하고 있습니다.
책에서 선정한 모델은 스테이블 디퓨전입니다. 이 모델은 독일 뮌헨의 루트비히 막시밀리안대학교의 콤프비스 그룹과 런웨이, 그리고 스타트업인 스태빌리티 AI라는 회사가 합작해서 마든 이미지 AI 모델입니다.
이를 통해서 이미지를 업로드하거나 텍스트로 설명을 통해서 이미지를 생성하는 간단한 어플리케이션의 실습에 대해서 소개하고 있습니다.
마치며…
기본적으로 책의 구성은 굉장히 좋았습니다. 5가지의 AI 서비서, 책 제목대로 쓸모있는 모델들에 대해서 소개를 해주었습니다. 알아야할 기술적 키워드, 모델, 실습으로 이어지는 구성을 통해서 쉽게 이해할 수 있었습니다. 더군다나 실습하는 내용들은 코드 형태로 설명을 하고 있어서 따라하면서 하나씩 익힐 수 있어 재밌기도 했습니다. 전반적으로 쉽게 읽을 수 있도록 난이도 조정이 잘되어있는것 같아서 AI에 관심있는 독자라면 누구라도 추천할만한 책인것 같습니다.
본 포스팅은 “한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다.”